Khosla, Savya, et al. "Magnet: Augmenting generative decoders with representation learning and infilling capabilities." Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025.
https://arxiv.org/pdf/2501.08648
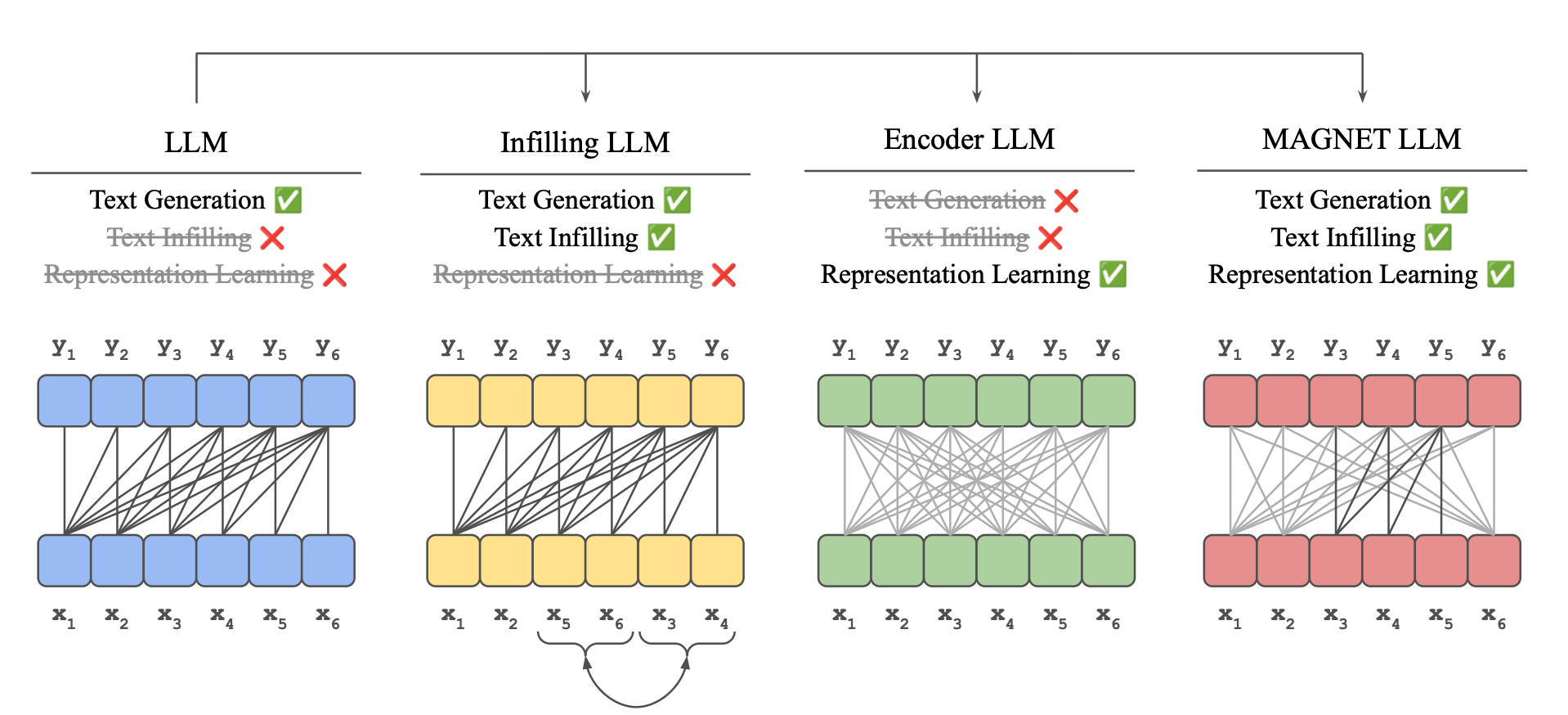
Abstract
LLM은 단방향 어텐션을 사용하는 생성 모델로 디자인되었지만, 양방향 어텐션도 활용할 수 있게 하는 접근법이 점점 많아지고 있다. 보통 단방향, 양방향 모델은 각기 다른 목적을 가지므로 따로 학습된다. 이러한 구분은 다목적 언어 모델 개발을 제한한다.
본 논문에서 제안하는 MAGNET은 LLM으로 강건한 표현(임베딩)을 생성할 수 있고, 빈칸 채우기(Text-Filling)를 할 수 있는 방법이다. 3가지 자기지도 학습 목적 함수와 단방향, 양방향 어텐션을 결합한 통합 학습을 가능하게 한다. LLM에 MAGNET을 활용하는 경우 다음과 같은 이점이 있다.
- 토큰-레벨과 문장-레벨 표현에서 뛰어난 임베딩 능력을 얻는다.
- 과거, 미래의 문맥을 모두 활용해서 적절한 텍스트를 생성해 빈칸을 채울 수 있다.
- 단어, 구문의 과도한 반복 없이 언어를 생성할 수 있다. (open-ended text generation)
- LLM 사전 학습 시 얻은 지식, 추론 능력을 보존한다.
1. Introduction
LLM은 학습이 효율적이고 확장 가능성을 가지므로 NLP에서 많이 사용된다. 하지만 단방향 어텐션으로 학습되므로, 양방향 문맥이 필요한 작업에서 추론 효과가 떨어진다. 양방향 문맥이 필요한 작업으로는 전체 문맥의 이해가 중요한 표현 학습 작업, 빈칸 채우기 작업 등이 있다.
최근 연구들은 표현 학습과 빈칸 채우기 작업에 LLM을 적응시키려고 시도했다. 하지만 빈칸 채우기 성능을 높이면 텍스트 임베딩의 성능은 떨어지고, 반대로 표현 학습에 집중하면 생성형 능력이 사라지게 된다.
이 논문에서 제안하는 MAGNET(Modified Attention for Generation and Encoding of Text)은 LLM이 생성형 능력을 보존하면서 표현 학습과 텍스트 채우기가 가능하게 한다. 이를 위해 3가지 자기지도 학습 목적 함수를 사용한다.
- 토큰-레벨 표현 학습을 위한 마스킹 모델링
- 문장-레벨 표현 학습을 위한 대조 학습
- 빈칸 채우기를 위한 누락된 정보 생성 능력
동시에 3가지 목적함수를 학습하기 위해 단방향, 양방향 어텐션을 모두 활용한 어텐션 마스크를 사용한다. MAGNET은 간단한 수정, 파인튜닝만으로 LLM에 적용되며, 모델별로 별도의 처리가 필요하지 않다. MAGNET-adapted Llama-2-7B는 토큰-레벨, 문장-레벨 표현 학습에 대해 LLM을 표현 학습에 활용하는 다른 방식을 넘어선다. 또한 MAGNET은 양방향 문맥을 고려할 수 있으므로 LLM보다 더 나은 빈칸 채우기 능력을 보인다. LLM을 인코딩용으로 학습했을 때 자주 발생하는 ‘반복 텍스트 생성 문제’에 대해서도 실험했으나, MAGNET-adapted 모델은 텍스트를 반복하지 않고 개방적인 텍스트 생성이 가능함을 증명했다.
2. Related Work
Representation Learning
텍스트 표현 학습은 문장 간 문맥 관계를 이해하는 것이 목표이다. 이 분야는 전통적으로 인코더 모델을 사용했는데, 두가지 구조 때문에 유리하기 때문이다. 토큰-레벨에서는 마스킹을 활용한 양방향 문맥 모델링, 문장-레벨에서는 유사도 기반으로 최적화가 된 스페셜 토큰 사용이 문맥을 이해하는데 유리하게 한다. 최근 LLM을 인코딩에 적용하려는 다양한 연구가 있었다. 모델 어휘 공간에 스페셜 토큰을 제공하는 것, 마지막 토큰([EOS]) 또는 mean-pooling을 사용해서 임베딩으로 사용, 마스킹 모델을 사용해서 파인튜닝, 라벨링 기반 지도학습 등의 접근들이 있었다. 이 중 몇가지 접근법은 단방향을 양방향 어텐션으로 바꾸지만 생성형 능력이 떨어지게 된다.
Text Infilling
빈칸 채우기 작업은 문장의 중간 내용을 생성하기 위해 빈칸 앞뒤의 문맥을 고려해야한다. 인코더-디코더 모델은 문맥을 인코딩하고, 이를 기반으로 텍스트를 생성하므로 빈칸 채우기가 가능하다. 또한 빈칸 채우기를 위해 문장의 일정 구간을 마스킹하는 확장된 마스킹 모델링 기법도 사용되었다. LLM이 활용된 빈칸 채우기 연구는 다음과 같다. LLM이 직접 빈칸을 채우게 학습하는 방법, 미래의 문맥을 참고할 수 있게 학습 예시 문장을 재배열하는 방법, 문장의 양쪽 끝에서 따로 텍스트를 생성하게 하는 방법 등의 접근들이 있었다. 이러한 접근법들은 빈칸 채우기 능력은 개선하지만 LLM의 표현 학습 능력은 개선되지 않는다.
Unifying Text Understanding and Generation
자연어 이해와 생성을 하나의 프레임워크로 통합하는 이전의 시도들은 주로 사전학습 목적함수를 제안하는데 집중했다. 사전 학습용으로 마스킹 모델링을 확장하는 접근법들이 많았다. 학습 시 문장을 구성하는 단어를 섞어서 양방향 문맥을 고려하게 하는 순열 기반 학습법, 문장의 가려진 구간을 autoregressive하게 채우는 학습법, 단방향과 양방향 어텐션 모두 사용하는 학습법, 인코더가 텍스트를 읽고 압축해서 디코더가 활용하는 Sequence-to-Sequence 학습법 등이다. 이런 접근법들은 새로운 모델을 사전학습해야하므로 기존의 LLM 인프라를 사용하지 못한다.
3. Method
LLM은 입력 시퀀스를 연속적인 블럭에서 처리한다. 이 중 self-attention 블럭에서는 입력 $x \in \mathbb {R}^{l \times d}$을 선형 변환해서 얻은 쿼리 $Q$, 키 $K$, 값 $V$로 어텐션을 계산한다.
$\text{Attn}_i(Q, K, V) = \text{softmax}\left(\frac{QK^T + M}{\sqrt{d_k}}\right)V$
- $\text{Attn}_i$ : multi-head self-attention의 i번째 head
- $d_k$ : key/query의 차원
- $M$ : causal 마스크 행렬
LLM에서 $l \times l$ 행렬의 순상삼각(Strictly upper triangular)이 causal 마스크이며, 이는 각 토큰이 자신과 이전 토큰에만 접근가능함을 의미한다. MAGNET은 LLM의 causal 어텐션에 양방향성을 추가하고 자기지도 목적함수를 사용해서 모델을 파인튜닝한다.
3.1 Modifying Attention
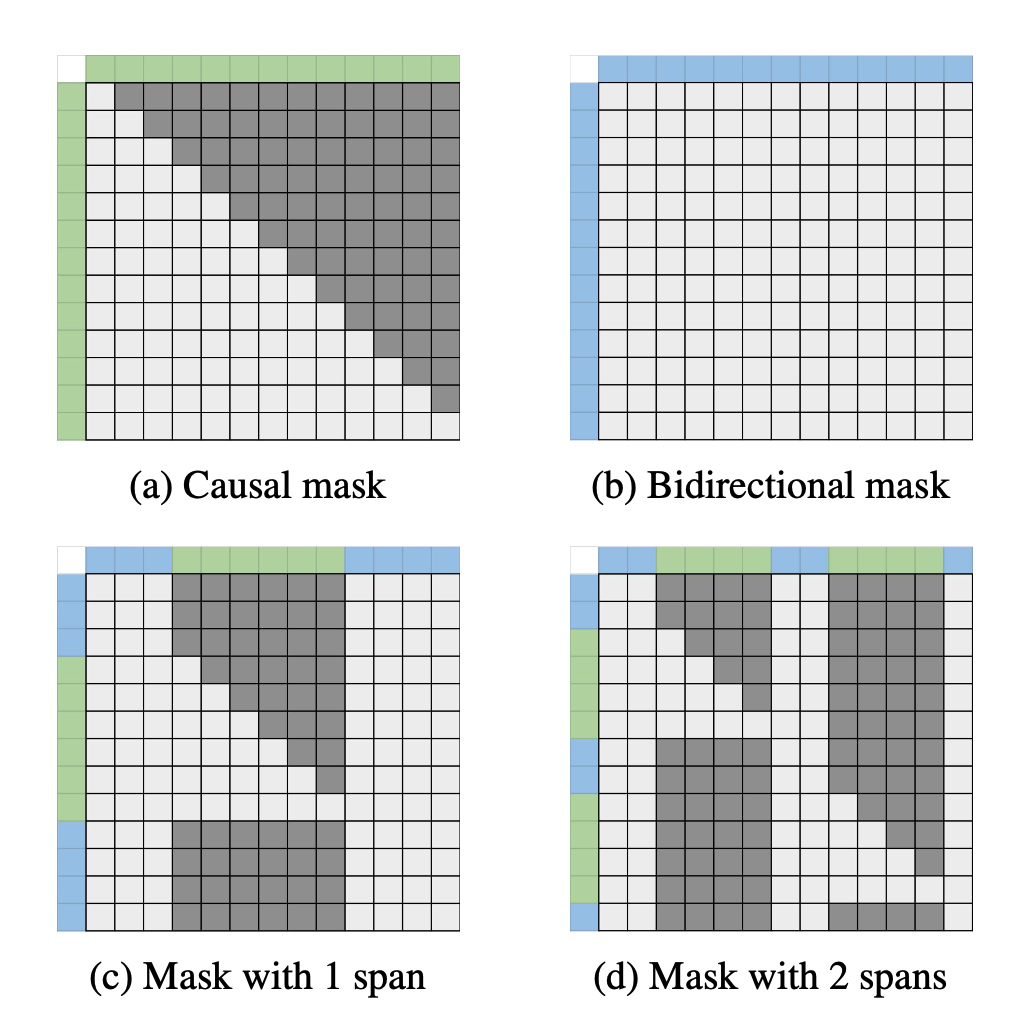
입력 토큰을 context token, span token으로 나눈다.
context token은 문장 내 모든 context token에 접근할 수 있다. 이는 단방향 LLM을 양방향 모델로 변경한다.
span token은 문장 내 연속적인 입력 토큰의 조합이다. 모든 context token에 접근 가능하고, 앞선 span token에만 접근 가능하다. 이를 통해 주변 컨텍스트를 활용할 수 있으므로, LLM은 빈칸 채우기 언어모델이 된다. span token 간에는 단방향성을 가지므로 LLM의 다음 단어를 예측하는 능력은 보존된다.
학습 시 입력 문장은 반드시 하나 이상의 span token을 가진다. span token 외의 나머지 토큰들은 context token이다.
3.2 Training Objectives

3.2.1 Masked Next Token Prediction(MNTP)
해당 loss 계산은 context token에 대해서만 진행한다. MNTP 기법은 모델이 활성화된 양방향 어텐션을 사용할 수 있게 한다. 입력 시퀀스 $x = (x_1, x_2, ..., x_L)$에 대해, 부분적으로 마스킹 토큰을 선택하고 이를 예측하게 모델을 학습한다. 입력 토큰의 20%를 마스킹 토큰으로 사용하며 마스킹 토큰 중 80%는 [MASK]로, 10%는 모델 어휘공간의 랜덤 토큰으로, 10%는 놔둔다. LLM은 다음 토큰을 예측하기 위해 학습되므로, $l$의 토큰 표현을 사용해서 $l+1$ 마스킹 토큰을 예측한다. $l$의 표현으로 $l$을 예측하는 MTP의 경우 자기회귀적이지 않으므로 오히려 성능이 떨어진다. MNTP는 categorical cross-entropy loss 수식 기반으로 최적화된다.
$\mathcal{L}{MNTP} = -\frac{1}{NL}\sum{n=1}^{N}\sum_{l=1}^{L}\sum_{v=1}^{V} \mathbb{1}{mask}(l+1) \cdot \left( y{lv}^{(n)} \log(\hat{y}_{lv}^{(n)}) \right)$
- N : 배치 사이즈
- L : 입력된 문장의 토큰 길이
- V : 모델의 어휘 공간 크기
- $\mathbb{1}_{mask}(l+1)$ : $(l+1)$번째 토큰이 마스킹되어 있으면 1, 아니면 0
- $y_{lv}^{(n)}$ : 실제 정답 확률
- $\hat{y}_{lv}^{(n)}$ : 모델이 예측한 확률
3.2.2 Self-Supervised Contrastive Learning (SSCL)
LLM은 전체 입력으로 문장-레벨의 표현을 생성하게 학습되지 않으므로, SSCL로 LLM을 텍스트 인코더로 만든다. 이 때 context token, span token 구분 없이 문장 전체를 사용한다. 입력 문장 $x$을 증강해서 $x^+$를 생성하고, 각각을 인코딩해서 임베딩 공간에서 서로 당기게 정렬 작업을 진행한다. 반대로 학습 배치에서 다른 입력 문장 인코딩을 멀리 배치하는 정렬 작업도 같이 진행한다.
$x^+$ 임베딩은 입력 문장 $x$를 의역해서 얻는다. 그리고 임베딩 표현은 모든 입력 앞에 “Given the sentence, find its representation:” 프롬프트를 모델에 입력해서, final hidden state의 마지막 토큰([EOS])를 사용한다.
토큰-레벨 최적화에서 이전 토큰으로 다음 토큰을 예측하므로, 마지막 토큰은 사용되지 않는다. 이 마지막 토큰은 문장-레벨 표현에 임베딩으로 사용되는데, 학습에 사용되는 각 토큰들이 분리되므로, 토큰-레벨과 문장-레벨의 표현 학습을 동시에 진행할 수 있다. loss 함수로는 InfoNCE를 사용한다.
$\mathcal{L}{SSCL}=\frac{-1}{N}\sum{i=1}^{N}\log\frac{\exp(e_i\cdot e_i^+/\tau)}{\sum_{j=1}^{N}\exp(e_i\cdot e_j^-/\tau)}$
- N : 배치 사이즈
- $\tau$ : logit scaling의 온도 매개변수
3.2.3 Missing Span Generation (MSG)
MSG는 LLM에 빈칸 채우기 능력을 제공한다. 빈칸 채우기는 주어진 위치 p와 입력 시퀀스 $x=(x_1,...,x_p,x_q,...,x_L)$에 대해 $x_p, x_q$ 사이의 그럴듯한 시퀀스 $y=(y_1, y_2 ... y_m)$를 생성하는 작업이다. 해당 논문에서는 모든 context token $x$와 이전의 span token $y_{[1..l-1]}$을 활용해서 span token $y_l$을 예측하게 학습 환경을 세팅한다. loss 함수로는 span token에 대한 categorical cross-entropy loss를 사용한다.
$\mathcal{L}{MSG} = -\frac{1}{N}\sum{n=1}^{N}\sum_{l=1}^{L}\sum_{v=1}^{V} \mathbb{1}{span}(l) \cdot \left( y{lv}^{(n)} \log(\hat{y}_{lv}^{(n)}) \right)$
- N : 배치 사이즈
- L : 입력된 문장의 토큰 길이
- V : 모델의 어휘 공간 크기
- $\mathbb{1}_{span}(l)$ : $(l)$번째 토큰이 span이면 1, 아니면 0
- $y_{lv}^{(n)}$ : 실제 다음 단어 정답 확률
- $\hat{y}_{lv}^{(n)}$ : 모델이 다음 단어 예측한 확률
입력이 span token만 있는 경우, causal 어텐션만 사용하므로 LLM의 보편적 기능인 다음 토큰 예측을 잘하게 된다. 따라서 모델의 텍스트 생성 능력도 유지하며 양방향성 표현을 배울 수 있다.
3.3 Approach Overview

학습 시 입력 $x$에서 다음 동작이 병렬적으로 수행된다.
- $x$에서 M개의 연속된 토큰 조합이 span token이 되며 ($x^m$), 나머지는 context token이 된다.
- $x^m$를 디코더 모델에 입력해서 hidden state $h^m$를 얻는다. $h^m$은 언어 모델링 헤드를 거쳐서 $y^m$을 생성하고, 이 값은 $\mathcal {L}{MNTP}$, $\mathcal {L}{MSG}$를 계산하는 데 사용된다.
- $x$를 증강해서 $x^+$를 얻는다.
- $x$, $x^+$를 디코더 모델에 입력해서 hidden state $h$, $h^+$를 얻는다. $h$, $h^+$는 projection head를 거쳐서 $e$, $e^+$ 표현을 얻으며, 이 값은 $\mathcal {L}_{SSCL}$의 연산에 사용된다.
$\mathcal {L} = \lambda_{1}\mathcal {L}{MNTP} + \lambda_{2}\mathcal {L}{SSCL} + \lambda_{3}\mathcal {L}_{MSG}$
(SSCL) $x$, $x^+$를 다룰 때는 양방향 어텐션 마스크를 사용한다. (MNTP, MSG) $x^m$을 다룰 때는 혼합된 어텐션 마스크를 사용한다.
4. Experiments
MAGNET이 LLM을 통한 표현학습과 빈칸 채우기 작업을 개선했으며, 생성 능력을 보존하고 있는지를 확인한다. 참고로 논문의 목적은 특정 벤치마크에서 SOTA를 달성하는 것이 아니라, 사전 학습된 LLM의 추가적 능력을 개선하되 기존 성능을 유지하는 것이다. 따라서 비교군은 기본 LLM과 다른 LLM을 활용한 방법론들이다.
4.1 Word-Level Tasks
평가 시에는 모델의 마지막 은닉층 위에 상위 선형 분류기를 둬서 모델의 표현으로 분류기를 학습시킨다. (Linear Probing) 이 때 단어 임베딩은 단어를 만드는 토큰 표현을 평균내서 얻는다. MNTP를 적용했으므로, $i$ 위치의 토큰 표현은 $i-1$ 위치의 임베딩을 통해 얻는다.
- 평가 작업 : chunking, named entity recognition, part-of-speech tagging
- 평가 데이터셋 : CoNLL-2003
- 비교 베이스라인 :
- Llama-2-7B (LLM-only)
- LLM2Vec (MNTP + SimCSE) : LLM을 임베딩에 활용하는 모델
- LLM2Vec[MNTP] (MNTP-only) : 문장-레벨 표현에 효과적인 SimCSE 모듈을 제거한 모델
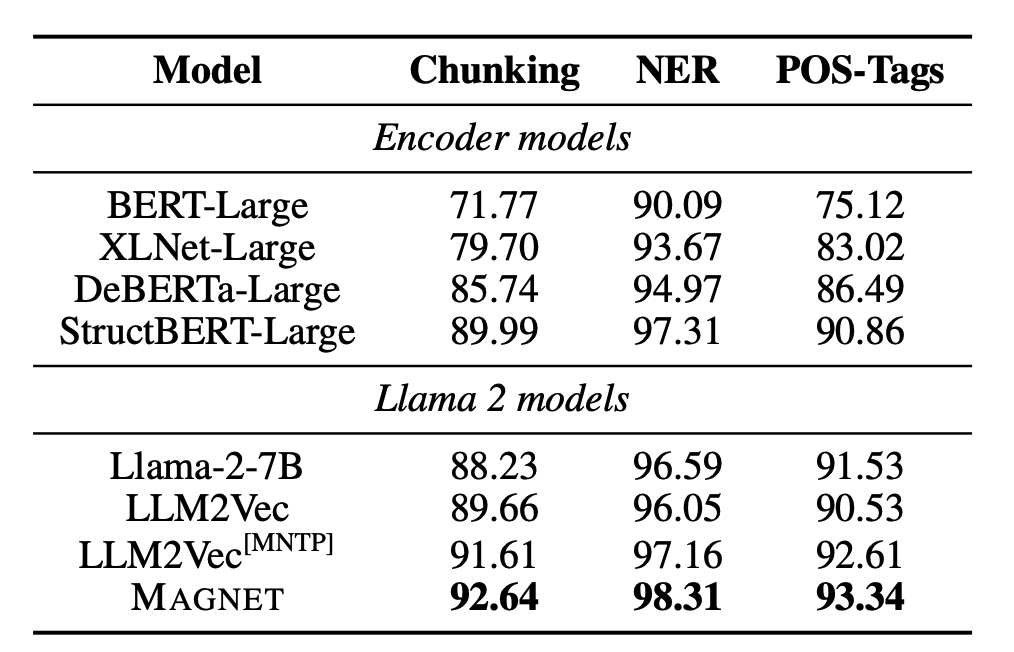
실험 결과 MAGNET은 LLM2Vec[MNTP]와 비교했을 때 더 뛰어난 토큰-레벨 표현을 만든다. LLM2Vec은 MNTP에만 의존하지만, MAGNET은 두가지 표현 학습 목적함수와 생성형 목적함수도 같이 학습에 사용함에 따른 시너지가 발생한다. 이 시너지는 MSG가 다음 토큰을 예측하는 LLM의 본래 학습과 유사하므로 표현 학습 시 값이 극단적으로 튀는 것을 막아주는 정규화 역할을 한 것으로 추측된다.
4.2 Sentence-Level Tasks
평가 시 마지막 은닉층의 마지막 토큰([EOS])을 문장-레벨 표현을 대표하는 항목으로 사용한다. 각 작업을 진행하기 위한 프롬프트만 모델에 추가로 입력한다.
- 평가 작업 : STS(Semantic Textual Similarity), Clustering
- 비교 베이스라인 :
- Llama-2-7B (LLM-only)
- LLM2Vec
- Echo Embeddings

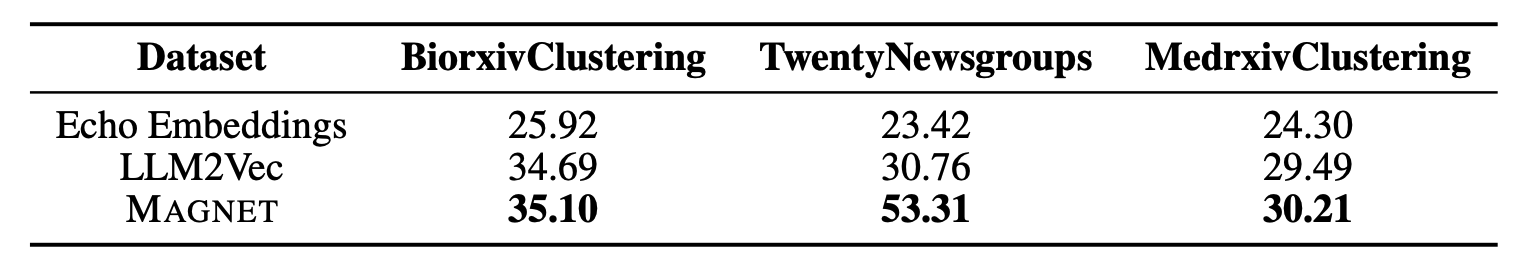
실험 결과 MAGNET은 STS와 Clustering 모두 가장 높은 성능을 보인다. 성능이 높은 원인 분석으로 논문에서는 통합된 학습 설계의 이점이라고만 설명하고 있다.
4.3 Infilling Task
빈칸 채우기 능력은 두가지 점수로 평가한다. 먼저 perplexity(PPL)이라는 예측 확신 점수를 활용하는데, 예측되는 다른 단어가 많은 경우 PPL은 높아진다. Span Token에 대해서만 PPL을 계산하여 평가한다. 다음으로 실제 사람이 이해가능하게 빈칸을 채우는지 확인하기 위해 human evaluation 평가를 추가로 진행한다. 두명의 검수자가 각각 생성된 문장의 일관성을 평가한다.
- 평가 데이터셋 :
- PPL
- RoC Stories : 5개마다 문장을 마스킹함
- Wikitext-103 : 3개의 연속된 토큰 조합(8~32 토큰)을 마스킹함
- Human Evaluation
- ROC Stories : 100개 스토리를 샘플링해서 중간 문장을 마스킹하고 모델이 빈 공간을 채움
- PPL
- 비교 베이스라인 :
- Llama-2-7B (LLM-only)


실험 결과 MAGNET은 Llama-2-7B와 비교 시 PPL 점수가 낮으며, 이는 빈칸 채우기 능력이 베이스 모델보다 뛰어남을 보인다. 또한 MAGNET이 채운 빈칸이 base 모델보다 더 높은 일관성 점수를 얻는다.
4.4 Repetition Problem
Repetition Problem은 생성형 모델이 동일한 내용을 반복적으로 생성하는 것이다. 해당 연구에서 생성형 디코더를 인코더로 쓸 수 있게 양방향 어텐션을 활성화하는 경우, 반복 문제가 더 심해진다는 것을 인지했다. 파인튜닝 데이터(Wikitext-103)에 문장 단위의 반복이 거의 없음에도, LLM2Vec에서 생성된 텍스트에는 상당한 문장 반복이 관찰된다. 반복을 파악하기 위한 지표로 $\text{Rep-Sen} = 1.0 - \frac{|\text{unique sentences}|}{|\text{sentences}|}$, $\text{Rep-n} = 1.0 - \frac{|\text{unique n-grams}|}{|\text{n-grams}|}$을 사용한다. 각각은 고유한 문장, 고유한 구문 개수를 통해 반복 생성률을 수치화한다. 값이 1에 가까울수록 반복이 많다.
- 평가 데이터셋 :
- Wikitext-103 : 5개의 단어를 제공하고 다음 텍스트를 생성하게 함
- ROC Stories : 한 문장을 제공하고 다음 텍스트를 생성하게 함
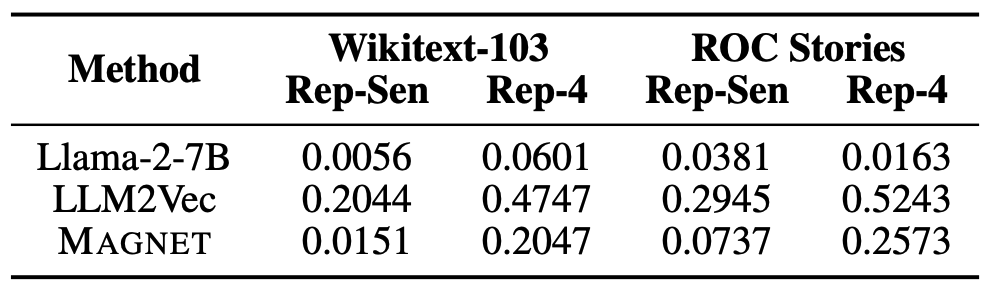
실험 결과 MAGNET은 LLM2Vec보다 LLM이 문장을 덜 반복하게 만든다. Wikitext-103에서 LLM2Vec은 LLM보다 36.5배, MAGNET은 LLM보다 2.7배 더 문장을 반복한다. 또한 학습 횟수에 따라 LLM2Vec은 점점 반복 생성이 많아지는데, MAGNET은 학습 횟수에 대한 반복 생성 경향이 없다. 반복 생성 문제는 BERT와 같은 양방향 언어모델에서 자주 발생하는데, MAGNET은 MSG 목적 함수에서 Span Token에 대해 단방향성도 학습하므로 이러한 문제를 덜 겪는 것으로 추측된다.
4.5 Knowledge and Reasoning Tasks
MAGNET 파인튜닝이 된 LLM이 사전 학습 때 얻은 지식, 추론 능력에 영향이 있는지 평가한다. 해당 평가에서는 파인튜닝 학습 데이터셋이 다른데, 사전 학습 데이터와 유사하게 하기 위함이다. 데이터 분포가 다르다면 모델의 성능과 별개로 지식, 추론 능력이 떨어질 수 있다.
- 학습 데이터셋 : SlimPajama (CommonCrawl, C4, Github, Books 등 다양한 종류의 문서 포함)
- 평가 데이터셋 : HellaSwag(0-shot), BBH(3-shot), ARC(0-shot), MMLU(5-shot), NaturalQuestions(5-shot)

실험 결과 MAGNET을 적용하는 것은 LLM의 지식, 추론 능력에 미세한 악영향만 준다. 사전 학습 시의 데이터를 알지 못하므로, 미세한 악영향도 파인튜닝 데이터셋과의 구성 차이가 원인일 수도 있다고 추측된다. 또한 (지식, 추론 능력을 유지하는) 해당 파인튜닝 모델에서 문장-레벨 표현학습 성능을 평가했을때도 높은 점수를 기록한다.
5. Conclusion
Contribution
- context token과 span token을 활용한 혼합 어텐션(MSG)를 활용하여, 빈칸 채우기 성능을 높이고 LLM 성능을 유지한다.
- MNTP와 SSCL에서 학습되는 토큰을 적절히 나눠서 각각의 표현 학습이 서로를 방해하지 않는다.
- MNTP는 마지막 토큰을 사용하지 않고, SSCL은 마지막 토큰으로 문장 표현을 생성함
Limitation
- LLM을 왜 Llama-2-7B 모델에 국한해서 사용하는지, 다른 LLM에서는 어떤 지 설명이 부족하다.
- 모델별로 성능이 일정하지 않거나 Repetition Problem을 해결하지 못했을 것으로 의심된다.
- LLM2Vec 이외의 다른 LLM기반 인코더(ex. GRITLM)와 성능 비교가 부족하다.
- 성능 개선 원인에 대한 깊이있는 분석 및 설명이 부족하다.